See also Codalab.org worksheet
But write below the line whatever you want to write and it will be transferred (by me) to the worksheet.
See https://worksheets.codalab.org/worksheets/0x432d360d644046428f7e230b08e384f6#
1) Shardlow, M., Zampieri, M. and Cooper, M. (2020) CompLex: A New Corpus for Lexical Complexity Prediction from Likert Scale Data. In Proceedings of the 1st Workshop on Tools and Resources to Empower People with REAding DIfficulties (READI). pp. 57-62.
From Wikipedia and News ->
Bible: We selected the World English Bible translation from Christodouloupoulos and Steedman (2015). This is a modern translation, so does not contain archaic words (thee, thou, etc.), but still contains religious language that may be complex.
Europarl: We used the English portion of the European Pariliament proceedings selected from europarl (Koehn, 2005). This is a very varied corpus talking about all manner of matters related to european policy. As this is speech transcription, it is often dialogical in nature.
Biomedical: We also selected articles from the CRAFT corpus (Bada et al., 2012), which are all in the biomedical domain. These present a very specialized type of language that will be unfamiliar to non-domain experts.
Team | Notes |
UnibucKernel | high-level features such semantic properties extracted from lexical resources and word embeddings, WordNet synsets PCA to reduce the dimension of the embeddings from 300 to 2 dimensions. The low-level features complex word, and include count of characters, count of vowels, count of consonants, count of repeating characters, and count of character n-grams (up to 4 characters) kernel-based learning algorithms are employed. For the binary classification setup, the SVM classifiers based on the Lib-SVM were used. For the regression setup, they used v-Support Vector Regression (v-SVR). |
SBGU | Features: feature selection is performed using the SelectFromModel feature selection method from scikit-learn library. The best performing features includes[a] word frequency, word sense and topics, and language model probabilities. :[b] 1) count and word form features such as length of the target, number of syllables, n-gram probabilities 2) morphological features, mainly part-of-speech tag and suffix length, 3) number[c][d] of synsets, number of hypernyms, and number of hyponyms, 4) context features, like topic distributions and word embeddings, and 5) psycholinguistic features Classifiers: Random Forest, Extra Trees, convolutional networks, and recurrent convolutional neural networks were tested. |
hu-berlin | Features: ”bag of n-grams”. Different lengths of n-grams such as a combination of 2-gram, 3gram, 4-gram, and 5-grams have been experimented with. The experimental results show that the combinations of 2-gram and 4-gram features are the best character level n-gram features for the binary classification task. Classifier: use of character n-gram features using a multinomial Naïve Bayes classifier specifically designed for the multilingual binary classification task. |
NILC | Features: Based on features (38 in total), word length, number of syllables, and number of senses, hypernyms, and hyponyms in WordNet. For N-gram features, probabilities of the n-gram language models trained on the BookCorpus dataset and One Billion Word dataset. 3 app 1) traditional feature engineering-based machine learning methods, 2) using the average embedding of target words as an input to a neural network, and 3) modeling the context of the target words using an LSTM. Linear Regression, Logistic Regression, Decision Trees, Gradient Boosting, Extra Trees, AdaBoost, and XGBoost classifiers. GloVe model XGBoost classifier for the binary classification task. LSTMs with transfer learning, |
TMU | Features: frequency features from the learner corpus (Lang-8 corpus) from Mizumoto et al. (2011) and from the general domain corpus (Wikipedia and WikiNews). classifiers: Random forest classifiers are used for the binary classification task while random forest regressors are used for the probabilistic classification task using the scikit-learn library. The systems perform very well both for the binary and probabilistic classification tasks, winning 5 out of the 12 tracks. |
ITEC | features: 5 different aspects (word embedding, morphological structure, psychological measures -MRC Psycholinguistic Database, corpus counts, and topical information)word2vec[e], with 300 dimensional embedding space, window-size of 5 and minimum frequency threshold of 20. Word embeddings are employed in two input layers, first to replace target words with the appropriate embeddings and second to represent the entire sentences as an input sequence which is considered the topical approximation using contextual cues. Classifier/DL Deep learning library with the tensorflow gpu as a backend. |
Camb | features: lexical features (word length, number of syllables, WordNet features such as the number of synsets), word n-gram and POS tags, and dependency parse relations. number of words grammatically related to the target word, psycholinguistic features from the MRC database, CEFR (Common European Framework of Reference for Languages) levels extracted from the Cambridge Advanced Learner Dictionary (CALD), and Google N-gram word frequencies using the Datamuse API The MCR features include word familiarity rating, number of phonemes, thorndike-lorge written frequency, imageability rating, concreteness rating, number of categories, samples, and written frequencies, and age of acquisition. Classifier: For the binary classification task, they have used a feature union pipeline to combine the range of heterogeneous features AdaBoost classifier with 5000 estimators achieves classifier of Random Forest. For the probabilistic classification task, the same feature setups are used and the Linear Regression algorithm is used to estimate values of targets. Tables 6, 7, 8, and 9, ranked first for English monolingual binary and probabilistic classification tasks. |
CoastalCPH | features: 1) log-probability features: unigram frequencies as a log-probabilities from language-specific Wikipedia dumps computed using KenLM, character perplexity, number of synsets, hypernym chain. 2) Inflectional complexity: number of suffixes appended to a word stem. 3) Surface features: length of the target and lower-case information. 4) Bag-of-POS: for each tag based on Universal Parts-of-Speech project, count the number of words in a candidate that belong to the respective class. 5) Target-sentence similarity: the cosine similarity between averaged word embeddings for the target word or phrase and the rest of the words Classifier/ML multitask learning applied[f] to the cross-lingual CWI task. ensemble that comprises of Random Forests (random forest classifiers for the binary classification task and random forest regressors for the probabilistic classification tasks, with 100 trees) and feed-forward neural networks. |
LaStus/Taln | 1) set of lexical, semantic and contextual features, A large set of shallow lexical and semantic features are also used in addition to the embedding features. T word length (number of characters), the position of the target word in the sentence, number of words in the sentence, word depth in the dependency tree, parent word length in dependency relation, frequency features based on the BNC,Wikipedia, and Dale and Chall list corpora, number of synsets and senses in WordNet, 2) word embedding features. The word embedding features are obtained from a pre-trained word2vec model1. For each sentence, the centroid of the dimensions of the context before the target word, the target word itself, and the context after the target word are computed using word2vec embedding vectors (300 dimensions each), resulting in a total of 900 feature dimensions. Classificator/ML: Weka machine learning framework using the Support vector machine Naïve Bayes, Logistic Regression, Random Tree, and Random Forest classification algorithms. The final experiments employ Support Vector Machines and Random Forest classifiers. |
CFILT IITB | Features: Lexical features based on WordNet for the target word are extracted as follows: 1) Degree of Polysemy: number of senses of the target word in WordNet, 2) Hyponym and Hypernym Tree Depth: the position of the word in WordNet’s hierarchical tree, and 3) Holonym and Meronym Counts: based on the relationship of the target word to its components (meronyms) or to the things it is contained in (Holonym’s). size-based features such as word count, word length, vowel counts, and syllable counts. They also use vocabulary-based features such as Ogden Basic (from Ogden’s Basic Word list), Ogden Frequency (Ogden’s Frequent Word List), and Barron’s Wordlist (Barron’s 5000 GRE Word List). Classifiers: 8 classifiers namely Random Forest, Random Tree, REP Tree, Logistic Model Tree, J48 Decision Tree, JRip Rules Tree, PART, and SVM. |
NLP CIC | Features: frequency counts of target word on Wikipedia, Simple Wikipedia, syntactic and lexical features, psycholinguistic features from the MRC psycholinguistic database and entity features using the OpenNLP and CoreNLP tools, and word embedding distance as a feature which is computed between the target word and the sentence. Classifiers/ML Tree learners such as Random Forest, Gradient Boosted, and Tree Ensembles are used to train different classifiers. DL 2D convolutional (CNN) and word embedding representations of the target text and its context is employed. |
Notes
Dataset:
todo: check - psycholinguistic features from the MRC database, CEFR (Common European Framework of Reference for Languages)
Cambridge Advanced Learner Dictionary (CALD)
Google N-gram word frequencies using the Datamuse API The MCR features
Absolute synonymy - “identity of meaning”
Definitions of synonymy and semantic representations
Storage of semantic representations
Relations and dependencies in language
Multiple phrasal elements and complex phrasal elements
Distributional Semantics Models
Dependency functions (Lexical functions)
Combined Logic-based and Distributional Semantics Models
Statistical similarity and synonymy
Methods of the relational approach
B - Dictionary - the definitional approach
Semantic Primes and Natural Semantic Metalanguage
Distributional Semantics Models
??Logic-based Semantics Models
Combined Logic-based and Distributional Semantics Models
WordNet and similar relation-driven projects
B - The definitional approach - dictionary
Semantic Primes and Natural Semantic Metalanguage
C - Distributional corpus-based methods (statistical semantics)
In general, if a word can be substituted by another without changing the meaning of the original sentence, the two words are similar and they pass the test for synonymy. As we can see in this example: “They live in a big/large house”, the two adjectives: “big” and “large”, can be considered as synonyms because substitution of one for the other does not change the overall meaning. (Lyons 1932, p. 63) However, “big” and “large” are not synonymous in all cases, as e.g., “You are making a big/large mistake”. Even single word-meaning depends on the closest context in which the word is situated and affects the meaning of the whole sentence.
We need a definition of synonymy that extends and differentiates between shades of meaning and thus enables for us a kind of evaluation of synonymy within the scale from “identity of meaning” to “similarity of meaning”.
To decide if two words, or broader statements, are the same, similar, or unrelated there has to be a stored prior representation of meaning and some processes for the evaluation of semantic similarity/identity. The attempts to derive meaning only from the words or statements themselves are like deciphering a text in an unknown language - almost impossible - as is the reality for many undeciphered scripts as Linear A, the Indus script, and the Phaistos Disc, (Robinson, 2002).
Lyons(cit) establishes that two words are “absolute synonyms” if they satisfy the following conditions:
(1) the meanings of all words are identical;
(2) the words are synonymous in all the collocational range of an expression;
(3) the words are semantically equivalent in all dimensions of meaning.
The first condition is known as the criterion interchangeability (S. Ullman) and defines synonyms as words “identical in meaning and interchangeable in any context".
The second condition served as a silent presumption for a wide range of distributional similarity and statistically based semantic representations (manning, mikolov - word2vec, glove etc). Sometimes it is called the weak distributional criterion of synonymy compared to the first strong condition (Apresjan 1957, Jones 1964, Lyons 1968). The second condition involves the set of all the contexts in which synonymous words can occur. The context here actively participates and induces meaning to restrain the similarity between words. These two conditions are stressed in the similarity computation first and foremost.
In the third Lyon’s condition, [g][h][i][j]the concept of meaning is introduced and puts an emphasis on semantic equivalence on all its dimensions.
Words that are more or less similar, but not identical in the sense of the first condition (full synonyms), are what may be called near-synonyms. Many of these words are listed as synonymous in a specialized dictionary or thesaurus. Near-synonymy is not to be confused with partial synonymy where the latter meets the criterion of the identity of meaning (1), but it fails, for various reasons, to meet the other two conditions. of what is generally referred to as very rare absolute synonymy.
Definitions of synonymy usually consider some concept of representation of meaning established a priori, but still, there is a wide spectrum of definitions based on various theoretical frameworks and it is very hard to quantify them... (linguistics, psychology, cognitive science, philosophy, anthropology) (Murphy p. 141).
The simple metaphor for distinguishing between two main approaches to storage of meaning is the following: thesaurus vs. dictionary (Murphy). The thesaurus iterates semantical relations between words and sorts them out into groups of related sets (e.g. synonyms, nouns, etc.). The dictionary defines words by breaking down their meanings into smaller parts and gives basic instructions on how to handle it. The dictionary model assumes a universal set of prime-meanings from which all other word-meanings are composed through a process of productive paraphrase(composition) or simplification.
For example word “eye”:
Dictionary model: These are two parts of your body. You can see because of these two body parts. “These are your eyes.”
Thesaurus model:
Related terms [organ;seeing;face;part,iris,see,vision],
Synonyms [oko,お目; עַיִן;näkö;ull;ア],
Parts of the eye [the cornea, aperture, an iris, canthus, central artery of the retina],
Antonyms [nose, mouth, ear, blind, lip][1]
Thesaurus and dictionary exist on a broad spectrum of theories that are more or less unintentionally combined.
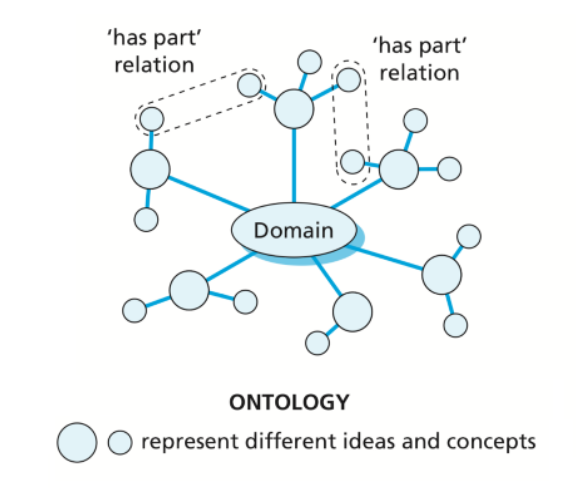
From one side of the spectrum, we have thesaurus theory where the word does not contain any definitional information at all. The word meaning arises purely through relations between words, in a lexical network, and from its unique position in the network (WordNet, in certain European structuralist linguistic positions, or philosophical positions) (Murphy 2003, p. 21) . (104 Murphy) Meaning is not “in” words, or in lexical entries, but it is distributed among them. The definition of the word is thus impossible to find (Fodor et al. 1975). Words as such can not be semantically analised and the meaning of the word is dependent on all the surrounding words with which the analyzed word enters into relations, recursively expanded further to all the words with which these words enter into relations, and so on. The word “girl” has certain relations with such words as “boy”, “man”, “child”, “pretty” and these relations are established as subjective and changing over-time facts.
On the other hand, we have dictionary theories as a representative of a pure componentialism. According to these theories we are able to list all word-meanings, all their senses, that can speaker think of, and there are no missing or unknown relations between words at all (as was presented in Chomsky’s generative linguistic (Chomsky 1965), but disproved by (Nunberg 1978): “All meanings cannot be listed because the potential semantic uses of a word is without limit.”).
The task becomes complicated when we acknowledge the fact that we, as humans, can simply fail to make an association between things we recognize and the words used to talk about these things. This is known as tip-of-tongue syndrome (“you know it is like a puppet, but it has no strings”). We can have complete access to the concept since you can imagine the recognized thing, to reason about it, and to describe it, but you are not able to access its proper name. That means that the storing and the accessing names of words is not the same as our means of storing and/or accessing other conceptual knowledge about the word. For example, “Dogs are used as sled pullers” is something I know about dogs, but it is not part of the meaning of “dog”. We will discuss meaning storages as collections of information about words rather than about things or ideas that words denote.
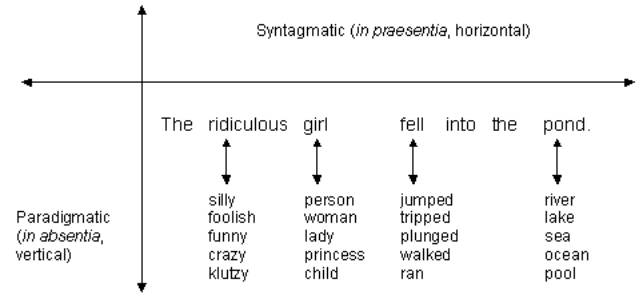
The single word meaning is established in the intersection of two types of relations: syntagmatic relations and paradigmatic (hierarchical) relations. This duality is supported by various studies presented by lexical semantics (42). Even if meaning and grammar are closely interwoven they are capable of being disentangled and then we are allowed to study individual lexical units, and their relations separately. On the contrary, we can compose meaning by sorting and layering individual lexical units.
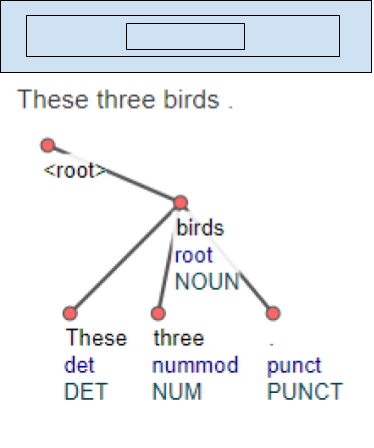
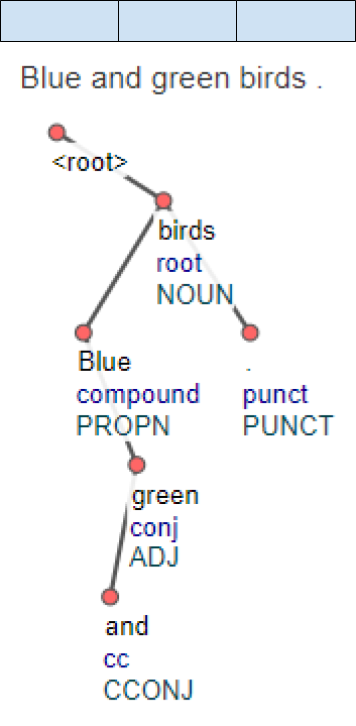
In Knowledge extraction applications(1), the term “phrase” refers to an established text combination of at least two elements. Elements (i.e., words) enter into relations and create constructions. We need to distinguish between two types of these constructions, between two types of phrasal elements: multiple phrasal elements and complex phrasal elements. They are both a combination of at least two elements with the same phrasal function and in one syntactic position; they differ in relating elements in sense of multiplication or hierarchical dependency (38, 39, 40). Thus the multiple phrasal element multiplies elements by way of coordination (40) and complex phrasal element creates a hierarchical structure within that consists of head and its dependents, and usually with fixed order.
Similar phrasal elements are idioms, but their meaning is non-compositional and cannot be simpy analyzed by the meaning of its components but rather as one (“Bite the bullet”)(2, 3, 4).
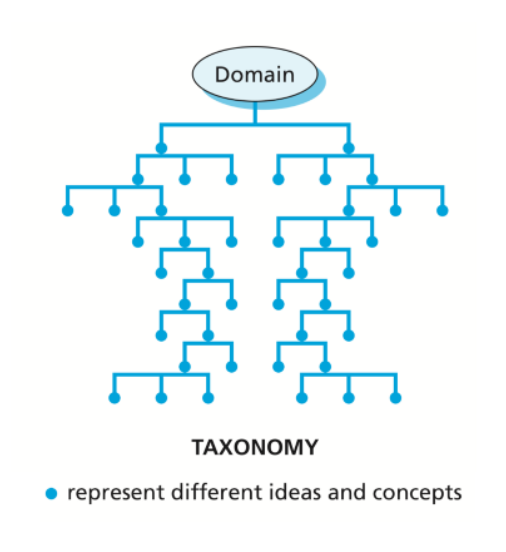
Determining the right kind of relation or dependency between words is central for constructing specialized semantic representations. Typically, representations are modeled as networks or taxonomies and where relations describe co-membership in a definable set.
Methods (104 Murphy) assume that meaning is not embedded “in” words, lexical entries or concepts, but among them. Definitions of words are impossible to find, and word definition cannot establish the meaning of the word. (Fodor et al. (1975). Words as such are semantically unanalyzable and the word’s meaning is dependent on all the words with which the word enters into relations (and, by extension, all the words with which those words enter into relations, and so on).
DSMs are linguistically anchored in theories between “structuralists” and “realists”(3). Words are not self-contained units packed with meaning, but only figurations and structured relations within the context bear meaning. The extreme interpretation is that the word without context doesn’t have any meaning at all and only relationships alone shape the word-meaning. We can experience even experience this in our everyday life as tip-of-tongue syndrome (“you know, it is like a puppet, but it has no strings”) as we can have a complete access to the concept, since you can picture the recognized thing, but you are not able to access its name - word. The relational meaning of “cow” is thus taken from contexts as “They are milking the cows”, “Cows give milk”(taken from Stubbs 2002: 15). The contexts here identify the properties of the word and his meaning. An analysis of collocations may be based on a word form or a lemma (all the inflectional forms of a word are treated as instances of a single lexical unit). Sinclair further specifies a term “colligation” as “the co-occurrence of grammatical choices” (1996: 85), i.e. the syntactic pattern with which a word appears. Co-occurrences are defined as membership of the analyzed word and syntactic class.
Theory of DSM refers to “Principle of extensionality”(cit) or “Distributional Hypothesis”(11). Distributional hypothesis states that two words that occur in similar contexts tend to have comparable meanings and that complex ideas are composed of a few simple ideas. Methods belonging to this approach can effectively detect and extract non-empirical terms (factoids), from different places of the text, and from different points of time and to present them as the united output (9, 10).
The distributional hypothesis is implemented by the Vector space model (VSM), a high-dimensional space, where each word defines one dimension, thus and a word’s coordinates represent its context (9, 12, 13). VSM applications attracted a great deal of attention lately (14), but VSM models in its uncombined form, seem to encounter its qualitative limit. The quantitative limit of the method is reached by limits of work and computations over sparse high-dimensional matrices. Partially can help Dimension Reduction Techniques (DRT)[k][l] by reducing the data to their “essence”, but at the high cost of losing context and valuable information. https://arxiv.org/abs/1608.01403
https://arxiv.org/abs/1811.00614
WordNets are databases organized by means of relations between words as are lexical relations (involving word forms and meanings) and as conceptual relations between synsets (involving meanings alone). The basic kind of relation in WordNet is synonymy which is by default treated as a lexical relation. One synset contains a group of synonyms e.i.: {car#1, auto#1, automobile#1, machine#6, motorcar#1}. If a word has more than one sense (e.i.: “bank” and “bank”), then it is represented in more than one synset. The synsets are related to one to another by means of paradigmatic relations. All words in one synset are mapped onto a single concept and there are no relations between concepts.
Nouns and verbs are represented in hierarchical structures, and adjectives are represented in a non-hierarchical format. Nouns in WordNet are organized by hyponymy/hyperonymy (bicycle belongs to a particular class wheeled objects), antonymy (adjectives with opposite meaning clear-unclear) and meronymy(word denoting a part of this object wheel-bicycle)/holonymy (G. Miller 1990, 1998b). Hyponymy and hyperonymy serve as the basic organizing principle for nouns, since all nouns participate in some class-inclusion relation. These are considered to be conceptual relations, rather than lexical relations, relating synsets rather than words. Thus in this approach synonymy is envisaged as a non-hierarchical symmetric paradigmatic relation, that means that, e.g., “couch” and “sofa” is not distinguishable from the relation between “sofa” and “couch”.
The first WordNet database was developed for english language by Princeton University (Miller et al. 1990; Fellbaum 1998b) and later in 2000 The Global WordNet Association (GWA) was established and nowadays GWA offers a growing number of wordnets in many languages (http://globalwordnet.org/).
https://www.sciencedirect.com/science/article/pii/S2095809919304928 Progress in Neural NLP: Modeling, Learning, and Reasoning
https://sci-hub.tw/https://doi.org/10.1007/s10462-018-9627-1 A review of conceptual clustering algorithms
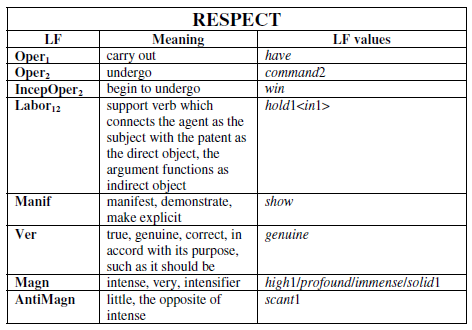
The lexical function maps a given keyword (argument) to a value expressing a specific meaning or a semantic-syntactic role. For example, the lexical function Oper (from Lat. operare, do) has the abstract meaning “do, perform, carry out something”. This meaning is present in the collocations “to deliver a lecture”, “to make a mistake”, “to lend support”, “to give an order”, therefore, they can be represented with one lexical function Oper (58).
LexicialFunction(keyword)=value
Oper(respect) = have
Labor(respect) = hold
manif(respect) = show
The Keyword chooses a particular value to express a certain meaning. E.g. “We make mistakes”, not “do mistakes”, or “lecture is delivered” and not “lecture is made”. Except meaning, lexical functions encode structural relations between keyword and its value (collocation). E.g. keyword “lecture” implies and an agent who delivers it and a recipient who receive it;
oper1(lecture) = to deliver; oper2(support) = to receive.
The subscript 1 indicates agent and subscript2 indicates recipient. For more than one semantic element can exist a complex lexical function with both agent and recipient. E.g. to put (somebody) under (somebody’s) control is represented as
CausOper2(control) = to put
where 2 specifies that the person put under control is the recipient of control, not its agent.
Lexical functions were originally introduced by Lyons(), only as a small set of paradigmatic lexical functions and with a relatively restricted set of meta-linguistic associations. Nowadays, lexical functions (58) are widely used to organize collocational data according to different types of lexical relations (DBnet, paraphrase, ...). Lexical functions may also relate lexical items to phrases and to other lexical items. e.g.: “joy” to “joyfully” and “yields with joy”.
Melcuk() presented Explanatory Combinatorial Dictionary (Mel’ˇcuk, Clas, and Arbatchewsky-Jumarie 1984–99) defined by using no more than 60 lexical functions(cit).
Apresjan() brings a further elaboration of complex lexical functions. The functions are divided into two main categories(59): as substitutions and parametric functions. The substitution function is a function of the paradigmatic axis and it indicates that value is a paraphrase of keyword and therefore it can be replaced one by another (value -> keyword ). Such substitutions are commonly found between synonyms, conversives, syntactic derivatives (words derived from So, Ao, Advo, Vo). Similarly, relationships between element keyword and its antonym or generic reference. Secondly, parametric function links element key word with others values(value1, value2, ...), and transform can transform its grammatical category e.g. from Funcs(wind)= to blow (the wind blows), Advs(rapid)=rapidly.
The idea of a definition comes from the assumption that there is an elementary set of basic and simple meaningful units that when composed together can define more complex units. These smallest meaningful units, and their folding, is limited by a set of compositional and decompositional rules. To reduce circularity in definitions (e.g., Katz and Fodor 1963; Bierwisch 1989; Jackendoff 1990; Pustejovsky 1995) there are two options, the first is to use rules other than the language rules, or the second, to start with limited number of units that bear the meaning - e.g. semantic primitives (Wierzbicka 1972, 1996). Semantic relatedness is then rated and detected by pattern matching. The theory for the word meaning composition and decomposition is supported by psycholinguistic evidence Bierwisch and Schreuder (1991).
Semantic primes (Wierbicka and Goddar) are the smallest units that are impossible to paraphrase in semantically simpler terms. By this starting point we get a set of basic building blocks from which the meaning of all other words can be explained in a non-circular manner (Wierzbicka 1996, Goddard and W 2014). Wierzbicka uses an initial list of 60 semantic primes. Every semantic prime has its own prefered “valency frames” - that creates “rules” for the prime how to behave. From semantic primes more complicated meanings (semantic molecules) are composed, or in other words defined. These definitions create extended frames of second level of composition and the process is called “reductive paraphrase”.
The complete speaker’s dictionary based exclusively on semantic primes and molecules is possible (Rodriguez 2020) and was presented in limited form by Bullock() as an excerpt of 2000 words definitions of the Longman dictionary. Unfortunately Semantic Primes theory still remains almost non-formalized theory.
The first layer consists of words representing 61 universal concepts expressed in all languages. This set of "semantic atoms" is based on the Natural Semantic Metalanguage (NSM), developed over the last three decades by Anna Wierzbicka and Cliff Goddard. The 34 middle layers consist of 300 "semantic molecules". Words in each layer are defined using only the words from the previous layers. This sequence of layers is based on dependency-graph analysis of the non-circular NSM-LDOCE research dictionary. The next layer contains definitions for the 2000 words in the Longman Defining Vocabulary, each defined using only the 360 "atoms" and "molecules" from the lessons. (The Longman Dictionary of Contemporary English can be considered the final layer, since every word is defined using only the 2000-word defining vocabulary.)
One way to reduce circularity in dictionary definitions is through the use of a controlled vocabulary. In the Longman Dictionary of Contemporary English (LDOCE), the definitions for over 80,000 words and phrases are written using only the central senses of around 2000 words in the dictionary's core defining vocabulary. This core vocabulary was developed from the General Service List of high-frequency words and their most common meanings (West, Michael. 1953. A General Service List of English Words. London: Longman).
The words appearing in LDOCE definitions are restricted to non-idiomatic uses of only their higher-frequency classes and senses. If a reader understands the 2000 words in the LDOCE's core defining vocabulary, the remaining 78,000 definitions in the LDOCE can be understood without encountering a circular reference.
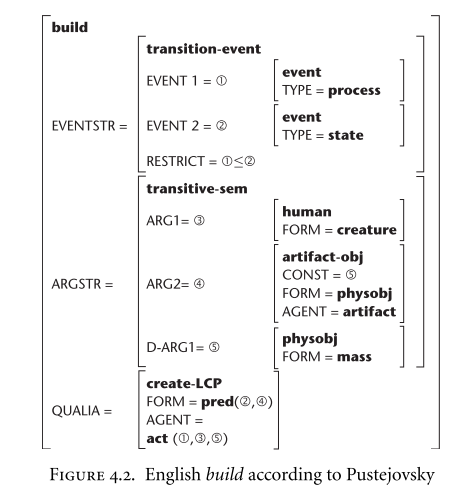
The most formalized componential model of contemporary semantics is Generative Lexicon proposed by Pustejovsky (1995a). The lexicon contains all lexemes (3,44) that a speaker of a given language knows and knows how to use them correctly. One lexicon entry contains syntactic information, semantic information, together with orthographic and morphological descriptions, as well as phonetic and phonological information. Generative lexicon concentrates primarily on syntactic relationship between lexemes and encoded semantic information. Semantic information identifies semantic classes under the lexical item belongs (entity/event/property), and also specifies semantic features of arguments and adjuncts of a lexical entry. The composed information for each lexicon entry is structured as following: the “argument structure” specifies the number and nature of the arguments of predicate; the “event structure” defines the event type of the expression and possibly also the internal event structure; and the “qualia structure” is a structured set of descriptive characteristics that corresponds most closely to the more traditional kinds of componential definition of meaning.(44,45). Generative lexicons serve as interfaces to inference and reasoning (52,53).
https://www.aclweb.org/anthology/W19-3318.pdf
https://www.aclweb.org/anthology/L18-1009.pdf
Example entry in Generative Lexicon for verb (46)
Others less extensive lexicon theories, as are Two-level approach and Jackendoff’s Conceptual Semantics, elaborate on an interface between the formal structures of a language and other, non-linguistic knowledge.??
[1] http://conceptnet.io/c/en/eye
[a]Typo?
[b]Either dot or comma?
[c]number maybe?
[d]was "umber", corrected to "number"
[e]Missing space.
[f]Changing "pplied" to "applied"
[h]?
[i]@dddd See now. I misunderstood my note. The problem was in "Lyon's" which should be "Lyons'
[j]Lyons'
[k]I don't think the concrete computional methods are needed here... I just loved to see their visualizations:)
[l]Techniques of computation (15, 16) are divided according to three main aspects/dimensions (17). 1) linear or nonlinear (e..g. Latent Semantic Analysis, Principal Component Analysis, Directed Graphs, Principal Curves, Neural Networks, Genetic and Evolutionary Algorithms, Regression). 2) by type of matrix that technique uses (e.g., covariance, term-document, term-context), and 3) the number of considered variables at once. Also among theorists nowadays rises interest about the meaning of the output of especially distributional models (9,12,13) and its measure.
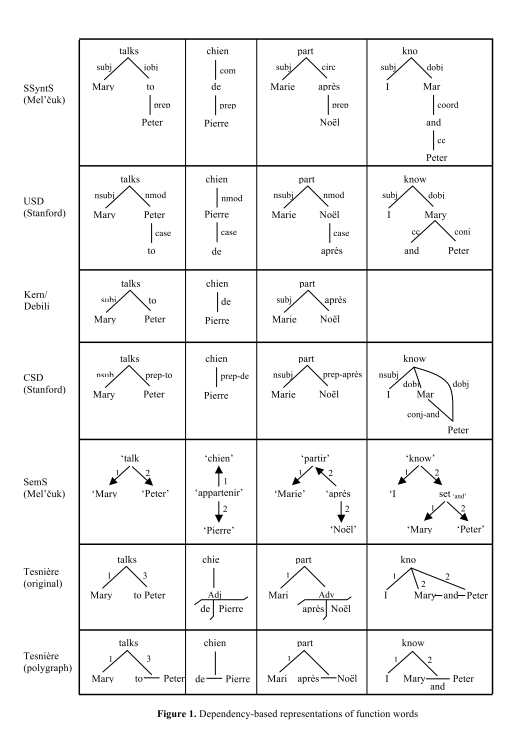
[m]Existuje celá plejáda jak závislostní funkce zapisovat... krásný přehled těch nejčastějších. Praha tu chybí samozřejmě:-/
[n]What is the source of this picture? Is it available somewhere in better quality (postscript or other vector-based format)?
[o]It is from an article, the article was not usefull at all but this schema I really like:) It connects a super computational DF from Stanford with Melcuk's. I will find it.
[p]definiton
[q]frames
[r]@[email protected] personally I think this is nonsense. The idea is nice but it mixes two, or more, operations together - meaning of words and meaning of statements